Software Metrics
우리는 항상 바쁘기 때문에, 남이 작성한 코드 및 전체 코드를 항상 주의 깊게 들여다보고 있을 수는 없다. 그렇다고 손을 놓고 있으면 코드가 쓰레기가 되기 때문에.. 코드의 그림자라도 계속 보고 체크해야할 필요가 있다. 이 때 활용할 수 있는게 코드 Metric이다. Sonargraph라는 코드 분석 툴에서 사용하는 대표적인 코드 Metric들을 정리해봤다.
Definition
Keyword
- 뜻을 가지고 있는, 언어 차원에서 예약된 고유명사
int, extern, enum, goto, if, switch, ...
Identifier
- 식별자. 변수명, 상수명, 함수명 등과 같이 사용자가 정의한 고유명사
int a = 0; // a는 Identifier void my_function() { // my_function은 Identifier }
Expression
- 수식이라고 보통 번역하는데, 하나 이상의 값으로 표현될 수 있는 코드는 모두 포함되기 때문에, 일반적인 수식의 개념과는 다르다. 하나의 값으로 표현될 수 있으면 모두 수식이기 때문에 함수 호출, 변수명과 같은 식별자, 배열 참조까지도 수식에 포함된다.
10 1 + 2 + 3 a + b a[2] get_value()
Statement
- if 문, for 문처럼 보통 ~문 이라고 번역하는데, 실행가능한 최소한의 코드 단위다. opcode로 표현되는 것들을 말한다고 보면 되려나.. 보통 한 개 이상의 키워드와 수식으로 만들어진다.
int a = 3; // Keyword + Expression a += 1; // Keyword + Expression if (a > 3) { // Keyword + Expression return; // Keyword }
Programming Element
- 타입, 필드, 메소드, 함수와 같은 선언 및 정의 요소
Source Element
- Programming Element 수 + Statement 수
Component
- 컴포넌트 만큼 맘대로 정의해서 사용하는 단어가 없을 것 같은데.. 일단, Sonargraph에서 컴포넌트는 물리적 파일 단위를 지칭한다. “Large Scale C++ Software Design”에서 John Lakos이 언급한 정의-“컴포넌트는 물리적 설계의 가장 작은 단위이다.”를 따른다고 한다. 보통 물리적 파일 단위로 클래스가 정의되니까 논리적 클래스 단위하고 어느정도 일치한다고 본다. C코드에서 제일 엉망진창 불일치할 가능성이 큰데.. 뭐 암튼.
Module
- 뭐 모듈도 마찬가지다. 오백만 개의 뜻으로 사용되고 있지만.. 여기서는 컴포넌트를 포함하는 배포 가능한 단위로 정의한다.(OSGi bundle, JAR file, C# assembly, …)
System
- 분석 범위를 나타내며 필요한 모든 리소스(workspace 정의, 가상 모델, analyzer 구성 및 Groovy 스크립트 및 분석 된 소스 코드, …)를 포함
Code Analysis
Average Block Nesting Depth
- 네스팅되어 있는 코드 블럭들의 평균 Depth. Depth가 깊어질수록 가중치를 주고 계산한다. 밥아저씨는 3갠가? 4갠가를 맥스로 잡았던 것 같은데.. 특별한 이유가 없으면 2개 이상 넘어갈 일이 별로 없긴 하다.
// Nesting Depth는 1 if (i > 0) { } // Nesting Depth는 2 if (i > 0) { if (j > 0) { } }
Component Dependencies to Remove
- 제거해야 할 컴포넌트 의존성 수. 컴포넌트 간 순환 의존 수를 모두 합산한 값이다.
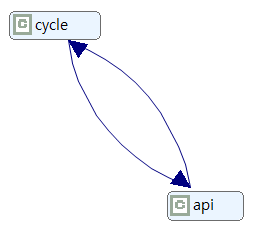
- Component Dependencies to Remove 1
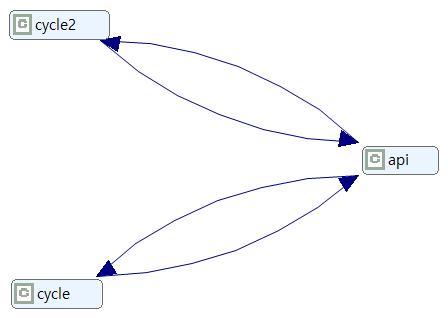
- Component Dependencies to Remove 2
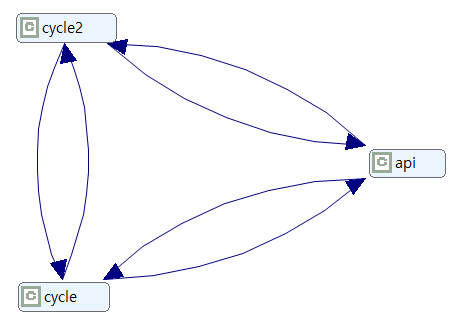
- Component Dependencies to Remove 3
Component Rank
- 컴포넌트의 순위. 구글의 PageRank 알고리즘을 따른다고 한다. 대충 후려치면.. 많이 참조되는 컴포넌트가 순위가 높단 얘기. 최대값은 100
![]()
- 대부분 컴포넌트에서 로그를 찍기 때문에 logger와 같은 컴포넌트는 Component Rank 값이 크다. common component가 값이 크다는 당연한 얘기.
Issue Density
- 이슈 밀도. 전체 코드량 대비 얼마나 이슈가 얼마나 많은가?를 나타냄.
- 해결되지 않은 이슈 수(에러+경고) x 1000 / 소스 요소 수(Source Element Count)
Number of Code Duplicates
- 중복된 코드 블럭의 수
Number of Duplicated Code Lines
- 중복된 코드 블럭 내 코드 라인 수의 합
Parser Dependencies to Remove
- 컴포넌트 간 순환 의존을 끊기 위해 수정해야 하는 코드 라인의 수
Structural Debt Index
- 컴포넌트 순환 의존의 누적된 구조적 빚
- 구조적 빚이란 순환 의존성, 아키텍쳐 위반, 임계값 위반, 재구성이 필요한 task수와 재구성 작업에 영향을 받는 코드 라인 수 등
- 기본적으로 하나의 구조적 빚을 해결하는 데 대략 5~10분의 노력이 든다고 가정(최소 단위) 한다. 실제로 하나의 구조적 빚을 해결하기 위한 비용을 계산할 때는 비용 계수를 곱해주는데 디폴트는 11 유로. 예를 들어 구조적 빚 지수가 1.162, 계수를 11이라고 한다면 구조적 빚을 개선하는데 드는 비용은 1.162 x 11 = 12.782 유로
Cycle
Cyclicity
- 시스템 내 모든 컴포넌트 순환 의존 수
Number of Component Cycle Groups
- 순환 의존을 갖는 컴포넌트가 여러개 모이면 하나의 닫힌 그룹의 형태가 되는데, 그 그룹의 수.
- 3개의 컴포넌트가 3개의 순환 의존을 가지고 있고, 1개의 Cycle Group을 형성하고 있다.
Number of Cyclic Components
- 순환 의존을 갖는 컴포넌트 수
Cohesion/Coupling
CCD(Cumulative Component Dependency)
- 각 컴포넌트가 직/간접적으로 의존하는 컴포넌트의 수를 모두 합산
- 컴포넌트 간 의존성을 최소한으로 유지해야 유연한 SW가 되므로 각 컴포넌트가 의존하는 컴포넌트의 수를 헤아려 볼 필요가 있다. John Lakos가 고안해 낸 간단한 계산법. 앞에서도 잠깐 언급했지만, John Lakos는 컴포넌트를 물리적 단위로 봤고.. CCD도 그에 기초한다. 즉, 물리적 파일간의 의존성을 계산한 것.
- 아래 그림에서 cycle2는 api에 의존하고, api는 cycle에 의존하고, cycle은 cycle2에 의존하므로 cycle2는 자기 자신 포함 직/간접적으로 3개의 컴포넌트와 의존관계를 가진다. 이런 방식으로 모든 컴포넌트의 의존관계 수를 계산하면, CCD = cycle2의 컴포넌트 의존 수 + cycle의 컴포넌트 의존 수 + api의 컴포넌트 의존 수 = 3 + 3 + 3 = 9
- 당연한 말이지만, 순환 의존을 갖는 컴포넌트가 많으면 많을 수록, CCD 값은 폭증한다. 당연히 좋지 않다.
ACD(Average Component Dependency)
- CCD / 전체 컴포넌트 수
- “평균 컴포넌트 의존 수” 정도의 의미가 되겠다.
Fan In Visibility
- 특정 컴포넌트에 의존하는(In 방향 의존성) 컴포넌트들이 얼마나 되는지 전체 컴포넌트 대비 퍼센트 비율로 나타낸 것
- 값이 클수록 많은 컴포넌트가 의존하고 있다는 뜻이니, 쉽게 변경할 수 없는 컴포넌트라는 것. 따라서 유지보수성이 떨어진다.
Fan Out Visibility
- Fan In Visibility와 반대. 특정 컴포넌트가 얼만큼 다른 컴포넌트들에 의존하고(Out 방향 의존성) 있는지 전체 컴포넌트 대비 퍼센트 비율로 나타낸 것.
LCOM4(Lack of Cohesion in Methods version 4)
- 1993년 Chidamber & Kemerer가 고안했고, Cohesion(응집도)를 측정하는 지표다. 2020년 현재 version 5까지 나와있는 상태.
- 간단히 말하면 클래스 내에서 의존 관계가 있는 메소드, 필드들 끼리 묶어서 그룹의 개수를 센 것이다. 잘 설계한 클래스라면 당연히 1개의 그룹만 나와야 한다. 클래스는 1개의 역할만 해야 하니까(Single Responsibility Principle). 여러개의 그룹이 나온다면 하나의 클래스가 여러 역할을 한다는 뜻이고 응집도가 떨어진다는 뜻이니, 클래스를 분리해야하는 것이 맞다.
- 유틸리티 클래스의 경우에는 LCOM4 값이 커질 가능성이 있다. “특별히 관계 없는 여러가지 기능을 모아 놓음 = 응집도 떨어짐” 이니 당연한 결과다. 유틸리티라는 말 자체가 모호하고 포괄적이지 않은가. 유틸리티 클래스 같은 것은 최대한 없애는 것이 맞다고 본다.
NCCD(Normalized CCD)
- 정규화된 CCD. 오키 정규화. 알겠는데.. 그럼 어떤 기준으로 정규화 시키느냐? 같은 수의 컴포넌트들이 balanced tree 구조로 의존하고 있다고 가정했을 때 구한 CCD 값이 기준이 된다. 예를 들어 컴포넌트 3개가 있는 시스템의 CCD 값이 9라고 했을 때, 컴포넌트 3개가 balanced tree 구조로 의존하고 있다면 CCD 값은 5가 되므로 NCCD 값은 9/5 = 1.8
- 의미를 생각해보면.. 뭐 기준이 되는 의존 구조가 balanced tree라고 가정하는 것이고, 그 구조일 때 CCD 값이 기준 값이 된다. 그 기준 값에 비해 실제 얼마나 CCD 값이 높은지 측정해보는 것이다.
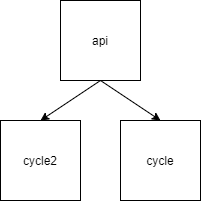
- Balanced Tree 의존 구조로 된 3개의 Components
- CCD = 3 + 1 + 1 = 5
- Cyclic 의존 구조로 된 3개의 Components
- CCD = 3 + 3 + 3 = 9
- NCCD = 위에 Balanced Tree 의존 구조의 CCD값이 5이므로 9 / 5 = 1.8
Propagation Cost
- MacCormack, Rusnak, Baldwin가 고안한 지표. 직/간접적으로 연결되어 있는 물리적 파일의 비율을 계산한다. 기본적으로 CCD와 동일한 개념.
RACD(Relative ACD)
- RACD = (ACD / 전체 컴포넌트 수) x 100
- ACD 값은 시스템 규모(전체 컴포넌트 수)에 영향을 받기 때문에 ACD 값 자체만 가지고는 의존도가 높다 낮다 얘기하기 어렵다. 따라서 ACD 값을 정규화시킬 필요가 있다. 시스템 규모(전체 컴포넌트 수) 대비 ACD 값이 얼마나 되나? 를 알기위해 RACD 값을 사용한다.
Comment Lines
- 주석 라인의 수
- 주석은 필요악
Lines of Code
- 공백과 주석을 제외한 코드 라인 수
Total Lines
- 공백과 주석을 포함한 전체 라인 수
Relational Cohesion
- 네임스페이스 내 컴포넌트의 의존 수 / 동일한 네임 스페이스 내 최상위 수준 논리적 Programming Element(타입, 필드, 메소드, 함수, …)의 수
- Craig Larman가 고안했고, 이 값이 높을 수록 프로그래밍 요소들 간에 종속이 많은 것이므로 응집도가 높다는 뜻. 프로그래밍 요소의 수는 많은데 그들 간에 종속성이 없다면 응집도가 떨어진다는 것이다.
Abstractness
- Robert C. Martin이 고안해낸 추상화 정도를 측정할 수 있는 지표
- 추상 클래스 수 / 구현 클래스 수
- 0~1사이 값이 되며, 당연하지만 값이 높을 수록 추상화도가 높은 것
Instability
- 역시나 밥아저씨가 만든 것으로, 외부에서 들어오는 의존성과 외부로 나가는 의존성의 비율을 0~1사이의 값으로 표현
- 외부로 나가는 의존성이 없으면 0. 들어오는 의존성만 있고 나가는 의존성이 없으니.. 쉽게 모듈을 못바꾼다. 이걸 안정(Stable)하다 라고 표현한다.
- 외부에서 들어오는 의존성이 없으면 1. 나가는 의존성만 있고, 들어오는 의존성이 없으니 쉽게 바꿀 수 있다. 이걸 불안정(Instable)하다 라고 표현한다.
Distance
- Abstractness + Instability - 1
- -1부터 1까지의 값(0으로부터의 Distance를 의미하는 듯). 0에 수렴할수록 좋음.
- Abstractness와 Instability의 합이 1에 가까워야 좋은 것이니, 추상화가 높으면 불안정도가 낮아야하고, 추상화가 낮으면, 불안정도가 높아야 함.
- -1에 수렴하면 고통스럽다. 추상화가 낮고, 불안정도도 낮으니… 구현으로 도배가 되어 있는데 변경이 어려운 상태. 따라서 고통스럽다.
- 1에 수렴하면 쓸모없다. 추상화가 높고, 불안정도가 높으니… 아무데나 쓸 수 있을정도로 너무 러프하게 추상화된 상태. 따라서 쓸모가 없다.
Cyclomatic Complexity
- Thomas J. McCabe가 고안
- 메소드 내에서 의사 결정 포인트(if나 switch 같은) 수 + 1(메소드 진입을 계산에 넣음)
Extended Cyclomatic Complexity
- Cyclomatic Complexity를 따르고, 추가로
&&와||의 수를 복잡도에 더한다.
Modified Cyclomatic Complexity
- Cyclomatic Complexity를 따르지만, switch 문은 case 수와 상관없이 복잡도를 1만 더한다.
Average Complexity
- Modified Cyclomatic Complexity의 가중 평균
- 예를 들어 A모듈은 메소드 100개, 복잡도 2. B모듈은 메소드 10개, 복잡도 10일 때, A모듈과 B모듈의 평균 복잡도를 계산한다면, 산술평균 = (2 + 10) / 2 = 6. 가중평균 = ((100 x 2) + (10 x 10)) / 110 = 2.7
Modified Extended Cyclomatic Complexity
- Cyclomatic Complexity를 따르지만, switch 문은 case 수와 상관없이 복잡도를 1만 더하고,
&&and||의 수를 복잡도에 더한다.
참조
- Sonargraph Manual
- Project Analyzer Manual
- Hello2morrow Blog
- Large-Scale C++ Software Design, John Lakos
- Design Principles and Design Patterns, Robert C. Martin