BIGPATENT: A Large-Scale Dataset for Abstractive and Coherent Summarization
Extractive 요약 데이터셋은 보통 (원문, 원문 내 요약문) 쌍으로 되어있다. 좋은 데이터셋의 핵심은 다양성(밸런스)이다. 요약문의 문장 구조가 다양하고, 다양한 단어들이 사용되었으며, 요약문이 원문 내 다양한 위치에 존재하는 것이 좋다. Google Big Query에 있는 특허 텍스트 데이터셋이 이런 조건을 만족한다고 해서 이 논문을 읽어봤는데, 얼마나 효과가 있는지는 모르겠다. 같은 Extractive 요약이라고 하더라도 해결하고자 하는 문제에 따라 데이터의 모양이 많이 달라지니까.
원문
Abstract
- 기존의 텍스트 요약 데이터셋의 문제점
- 뉴스 기사에 한정
- 요약문이 구조적으로 단순해서 입체적이지 않음
- 대부분 원문의 앞 부분이 요약일 경우가 많음
- 원문의 큰 덩어리 부분이 그대로 요약이 되버리는 경우가 있음
- BIGPATENT 데이터셋의 특징
- 130만 건의 미국 특허
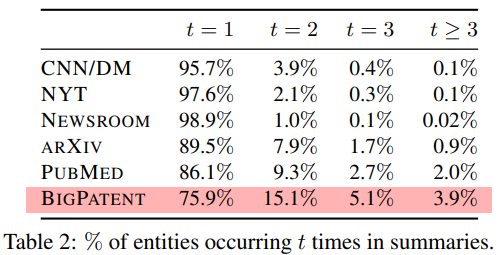
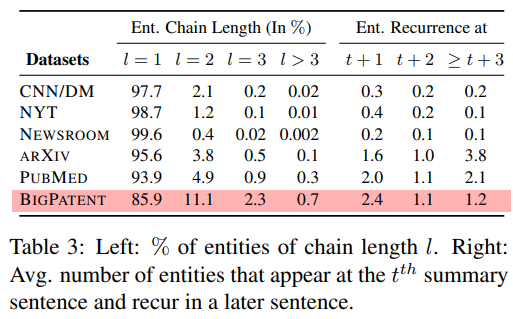
- 요약문이 풍부한 문장 구조를 가지며 중요 단어는 자주 출현함
- 중요 내용이 원문의 앞,중간,뒤에 골고루 배치되어 있음
- 원문에서 추출한 문장 조각의 길이가 더 짧음(큰 덩어리로 추출되지 않음)
1. Introduction

- 색깔은 동일하게 등장하는 단어를 표시
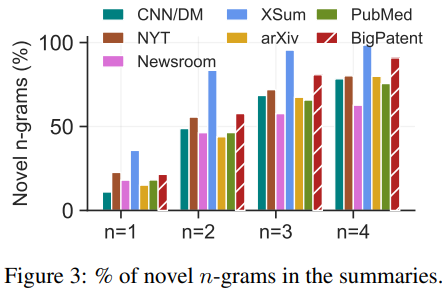
- BIGPATENT 요약문에 중요 단어가 더 많이 반복적으로 출현함
- 밑줄은 원문에서 그대로 추출된 문장 조각
- BIGPATENT 요약문에 출현하는 문장 조각의 길이가 이 더 짧음
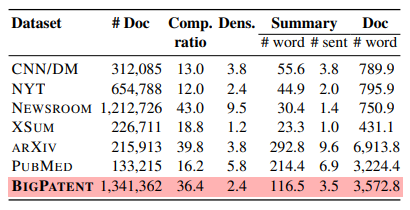
- 데이터셋의 통계 수치
- Doc = 원문의 수
- Comp. ratio = Compression ratio(압축률) = 요약문의 단어 수/원문의 단어 수
- Dens. = Density(밀도) = 원문에서 그대로 추출되어 요약문에 포함된 문장 조각의 평균 길이
- BIGPATENT는 요약문의 길이도 길며, 원문의 긴 문장 조각을 그대로 가져오지도 않은 편
2. Related Work
3. BIGPATENT Dataset
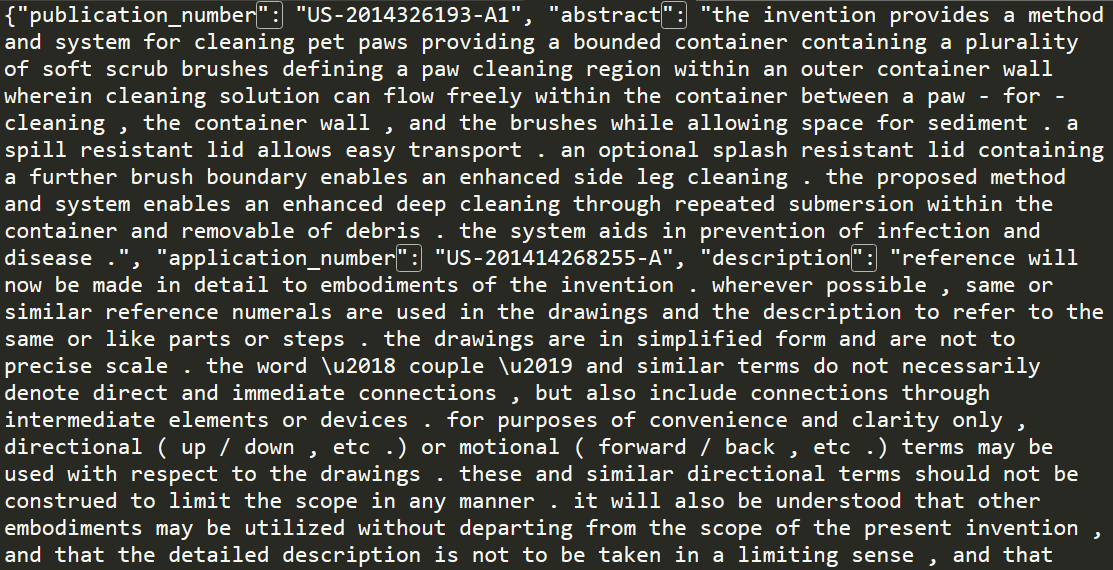
- Google Big Query에서 9개 분야의 1971년 이후 미국 특허 데이터 130만건 수집
- 특허의 Description을 원문으로, 특허의 Abstract를 요약으로 사용
4. Dataset Characterization
4.1 Salient Content Distribution
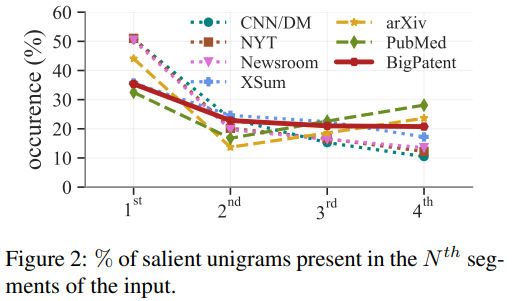
- 중요 단어가 출현한 문단
- BIGPATENT는 중요 단어가 1,2,3,4번째 문단에 비교적 고르게 분포하고 있음
4.2 Summary Abstractiveness and Coherence