Text Summarization with Pretrained Encoders
현재 프로젝트에서 BERT의 NER과 Sentence Classification을 사용하고 있는데, Summarization이 필요하게 됬다. Summarization은 Abstractive와 Extractive로 나뉘는데, Abstractive는 생성 분야라 BERT를 그대로 사용하기엔 무리가 있다. GPT나 다른 알고리즘을 알아보기 전에, 일단 BERT를 활용해서 Abstractive Summarization 하는 방법을 알아봤다.
원문
Abstract
- BERT can be usefully applied in text summarization and propose a general framework for both extractive and abstractive models.
- 버트를 약간 변형해서 문장 추출 요약/추상화 요약 프레임워크로 만들 수 있다.
- Our extractive model is built on top of this encoder by stacking several intersentence Transformer layers.
- 추출 요약 모델은 인코더위에 몇개의 트랜스포머 층을 쌓아 만든다.
- For abstractive summarization, we propose a new fine-tuning schedule which adopts different optimizers for the encoder and the decoder as a means of alleviating the mismatch between the two(the former is pretrained while the latter is not).
- 추상화 요약 모델은 파인튜닝할때 인코더, 디코더에 각각 다른 옵티마이져를 두어 만든다. 인코더는 사전학습된 상태이지만 디코더는 아니기 때문에 파인튜닝할 때 발생하는 학습 불균형을 완화시키기 위해서다.
- We also demonstrate that a two-staged fine-tuning approach can further boost the quality of the generated summaries
- 추가로 2단계 파인튜닝 접근법을 사용했다.
Introduction
- under abstractive modeling formulations, the task requires language generation capabilities in order to create summaries containing novel words and phrases not featured in the source text
- 추출 요약은 원문에 있는 문장 중 중요한 문장을 그대로 뽑아내는 것이다.
- 추상화 요약은 원문에 없는 단어나 구문을 생성하는 것이다.
- while extractive summarization is often defined as a binary classification task with labels indicating whether a text span(typically a sentence) should be included in the summary.
- 보통 추출 요약은 요약에 꼭 들어가야만하는 문장을 레이블링해서 학습시키는 이진 분류 문제이다.
- we present a two-stage approach where the encoder is fine-tuned twice, first with an extractive objective and subsequently on the abstractive summarization task
- 2단계 파인튜닝의 정체는 인코더를 추출 요약으로 한번, 추상화 요약으로 또 한번 파인튜닝하는 것이다.
Background
Pretrained Language Models
Extractive Summarization
- Extractive summarization systems create a summary by identifying (and subsequently concatenating) the most important sentences in a document. Neural models consider extractive summarization as a sentence classification problem.
- 추출 요약은 문서 내 가장 중요한 문장을 뽑아내 묶는것이다. 신경망에서는 분류 문제로 다룬다.
Abstractive Summarization
- Neural approaches to abstractive summarization conceptualize the task as a sequence-to-sequence problem
- 추상화 요약은 seq2seq 문제로 본다.
Fine-tuning BERT for Summarization
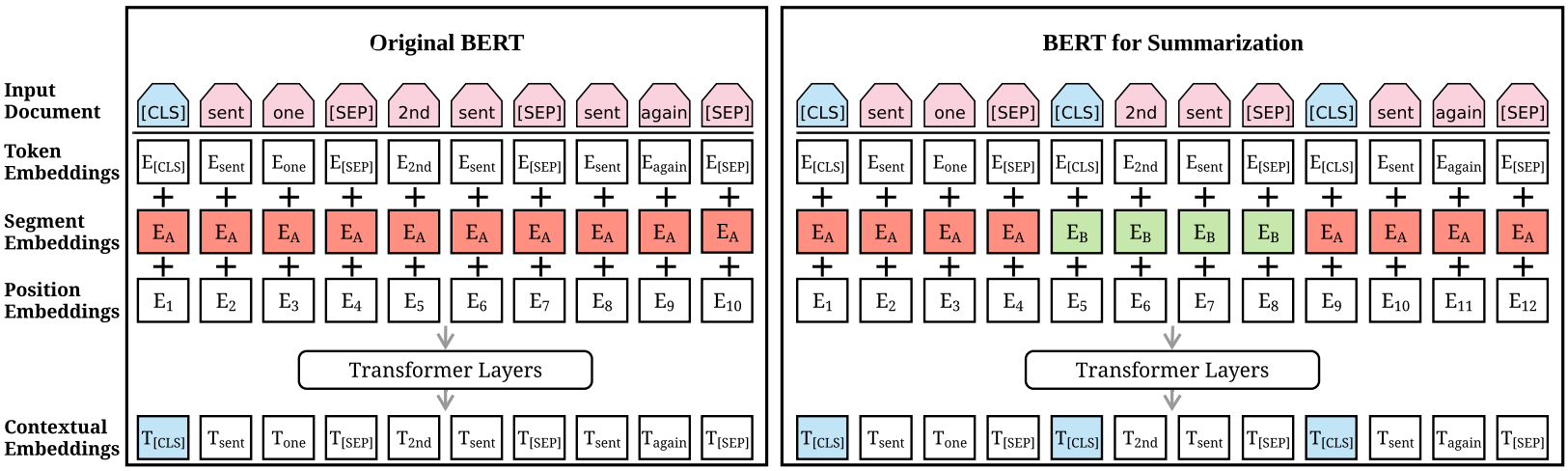
- Although BERT has been used to fine-tune various NLP tasks, its application to summarization is not as straightforward. Since BERT is trained as a masked-language model, the output vectors are grounded to tokens instead of sentences, while in extractive summarization, most models manipulate sentence-level representations.
- 다양한 Task에서 버트를 파인튜닝해서 쓸 수 있지만, 요약 문제에서는 쉽게 쓰기 어렵다. 왜냐하면 버트는 masked 언어 모델이라서 출력 벡터가 문장보다는 토큰을 표현하는데, 요약에서는 문장 표현이 필요하기 때문이다.
- Although segmentation embeddings represent different sentences in BERT, they only apply to sentencepair inputs, while in summarization we must encode and manipulate multi-sentential inputs.
- 버트에서 [SEP]를 통해 문장을 구분해 임베딩할 수 있지만, 2개의 문장만 구분할 수 있다. 요약에서는 2개가 아닌 여러개의 문장을 인코딩해야한다.
- In order to represent individual sentences, we insert external [CLS] tokens at the start of each sentence, and each [CLS] symbol collects features for the sentence preceding it.
- 개별 문장을 구분해 나타내기 위해, 매 문장 앞에 [CLS] 토큰을 넣었다.
- We also use interval segment embeddings to distinguish multiple sentences within a document
- 각 문장은 세그먼트 임베딩도 달라야하기 때문에 인터벌 세그먼트 임베딩(홀수번째 문장은 세그먼트A, 짝수번째 문장은 세그먼트B)을 했다.
- This way, document representations are learned hierarchically where lower Transformer layers represent adjacent sentences, while higher layers, in combination with self-attention, represent multi-sentence discourse.
- 트랜스포머의 낮은층(입력층에 가까운 쪽)은 인접 문장을 표현하고, 셀프 어텐션이 조합된 높은 층은 여러 문장과의 관계를 표현한다.
- Position embeddings in the original BERT model have a maximum length of 512; we overcome this limitation by adding more position embeddings that are initialized randomly and finetuned with other parameters in the encoder.
- 버트의 위치 임베딩 최대 값은 512인데, 무작위로 초기화되고 인코더의 다른 파라미터로 파인튜닝되는 위치 임베딩을 추가하여 이 한계를 극복한다.(?)
Extractive Summarization
- Let d denote a document containing sentences [sent1, sent2, · · · , sentm], where sent-i is the i-th sentence in the document. Extractive summarization can be defined as the task of assigning a label y-i ∈ {0, 1} to each sent-i, indicating whether the sentence should be included in the summary.
- 문서는 [문장1, 문장2, 문장3, ..문장m] 이렇게 구성되고, 각 문장은 0 또는 1로 레이블링 된다. 1은 추출 요약에 포함, 0은 추출 요약에 불포함. 이진 분류 문제이다.
- With BERTSUM, vector t-i which is the vector of the i-th [CLS] symbol from the top layer can be used as the representation for sent-i. Several inter-sentence Transformer layers are then stacked on top of BERT outputs, to capture document-level features for extracting summaries
- 벡터 t-i는 i번째 [CLS] 심볼로부터 시작되는 문장을 표현한다. 버트의 인코더 출력층에 몇개의 트랜스포머 층을 더 쌓아서 문서 수준의 특징을 잡아낸다.
- h0 = PosEmb(T); T denotes the sentence vectors output by BERTSUM, and function PosEmb adds sinusoid positional embeddings (Vaswani et al., 2017) to T, indicating the position of each sentence.
- 트랜스포머 층의 입력은 문장 벡터T에 위치 임베딩을 한 벡터이다.
- In experiments, we implemented Transformers with L = 1, 2, 3 and found that a Transformer with L = 2 performed best. We name this model BERTSUMEXT.
- 실험 결과, 트랜스포머 층은 2개를 쌓았을 때 성능이 제일 좋았다. 이를 BERTSUMEXT라고 부르기로 했다.
- The loss of the model is the binary classification entropy of prediction y-i against gold label y-i.
- 손실 함수는 이진 분류(레이블링과 예측의 차이)의 엔트로피를 계산한다.
- We use the Adam optimizer
- 아담 옵티마이져를 사용하며 파라미터는 아래와 같다.
- Our learning rate schedule follows (Vaswani et al., 2017) with warming-up
- warming-up 사용하며, 학습률 설정은 아래와 같다
Abstractive Summarization
- We use a standard encoder-decoder framework for abstractive summarization (See et al., 2017). The encoder is the pretrained BERTSUM and the decoder is a 6-layered Transformer initialized randomly.
- 표준 인코더-디코더 모델을 사용한다. 인코더는 사전학습된 BERTSUM, 디코더는 랜덤하게 초기화된 6개의 트랜스포머 층이다. It is conceivable that there is a mismatch between the encoder and the decoder, since the former is pretrained while the latter must be trained from scratch. This can make fine-tuning unstable; for example, the encoder might overfit the data while the decoder underfits, or vice versa. To circumvent this, we design a new fine-tuning schedule which separates the optimizers of the encoder and the decoder.
- 인코더는 사전학습되었지만, 디코더는 바닥부터 학습해야하므로, 학습시 인코더가 오버피팅되거나 디코더가 언더피팅될 수 있다. 이를 해결하기 위해 인코더,디코더에 각각 다른 학습률을 적용한다.
- Adam optimizer
- Encoder learning rate
- Decoder learning rate
- This is based on the assumption that the pretrained encoder should be fine-tuned with a smaller learning rate and smoother decay (so that the encoder can be trained with more accurate gradients when the decoder is becoming stable).
- 디코더가 큰 학습률로 팍팍 학습하는 동안 인코더는 세밀하게 학습한다.
- In addition, we propose a two-stage fine-tuning approach, where we first fine-tune the encoder on the extractive summarization task (Section 3.2) and then fine-tune it on the abstractive summarization task (Section 3.3). Previous work (Gehrmann et al., 2018; Li et al., 2018) suggests that using extractive objectives can boost the performance of abstractive summarization.
- 인코더를 추출 요약 모델로 한번 파인튜닝하고, 추상화 요약으로 한 번 더 튜닝하면 성능이 좋아진다.