BERT(Bidirectional Encoder Representations from Transformers)
그 유명한 BERT 논문이다. BERT를 설명한 글과 영상은 많지만 그래도 논문은 한 번 정독해야 하지 않나 싶어서 정리해봤다.
원문
Abstract
- We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers.
- 트랜스포머 기반의 양방향 인코더
- BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers.
- 레이블링되지 않은 텍스트를 양방향으로 사전 학습했다.
- As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications.
- 하나의 출력 레이어만 추가하여 finetuning 하면, 아키텍쳐 변경 없이 다양한 NLP 모델을 만들 수 있다.
- BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).
- 11개의 NLP 작업에서 state-of-the-art 달성했다.
Introduction
- Language model pre-training has been shown to be effective for improving many natural language processing tasks (Dai and Le, 2015; Peters et al., 2018a; Radford et al., 2018; Howard and Ruder, 2018). These include sentence-level tasks such as natural language inference (Bowman et al., 2015; Williams et al., 2018) and paraphrasing (Dolan and Brockett, 2005), which aim to predict the relationships between sentences by analyzing them holistically, as well as token-level tasks such as named entity recognition and question answering, where models are required to produce fine-grained output at the token level (Tjong Kim Sang and De Meulder, 2003; Rajpurkar et al., 2016).
- 언어 모델의 사전 학습은 문장 처리 task와 토큰 처리 task에 모두 효과적임이 증명되었다.
- There are two existing strategies for applying pre-trained language representations to downstream tasks: feature-based and fine-tuning. The feature-based approach, such as ELMo (Peters et al., 2018a), uses task-specific architectures that include the pre-trained representations as additional features. The fine-tuning approach, such as the Generative Pre-trained Transformer (OpenAI GPT) (Radford et al., 2018), introduces minimal task-specific parameters, and is trained on the downstream tasks by simply fine-tuning all pretrained parameters.
- 현재 사전 학습된 언어 표현을 적용하는 방식에는 feature-based와 fine-tuning 2가지가 있다.
- feature-based 방식은 원하는 task에 맞게 따로 아키텍쳐를 만든다. 이 아키텍쳐에 사전 학습된 표현들을 이용한다. ELMo 등이 이런 방식.
- fine-tuning 방식은 원하는 task에 맞는 파라미터만 선택하고 아키텍쳐는 변경하지 않는다. downstream task에서 학습하면서 선택한 파라미터 값들을 미세 조정한다. OpenAI GPT 등이 이런 방식.
- The two approaches share the same objective function during pre-training, where they use unidirectional language models to learn general language representations. We argue that current techniques restrict the power of the pre-trained representations, especially for the fine-tuning approaches. For example, in OpenAI GPT, the authors use a left-to right architecture, where every token can only attend to previous tokens in the self-attention layers of the Transformer (Vaswani et al., 2017).
- 이 두가지 방식은 모두 단방향으로만 텍스트를 학습하는데, 이는 사전 학습 방식의 강력함을 제한한다. 특히 fine-tuning에서는 더 그렇다.
- OpenAI GPT 예를 들면, 트랜스포머의 셀프 어텐션 레이어에서 앞에 출현하는 토큰들은 뒤에 출현하는 토큰들에 대한 어텐션 값을 가지지 못한다. Transformers 디코더의 셀프 어텐션 참조
- Such restrictions are sub-optimal for sentence-level tasks, and could be very harmful when applying finetuning based approaches to token-level tasks such as question answering, where it is crucial to incorporate context from both directions.
- 이는 문장 처리 task들에 좋지 않고, 양방향 문맥 통합이 중요한 토큰 처리 task들에 finetuning 방식을 적용할 때, 매우 좋지 않다.
- In this paper, we improve the fine-tuning based approaches by proposing BERT: Bidirectional Encoder Representations from Transformers. BERT alleviates the previously mentioned unidirectionality constraint by using a “masked language model” (MLM) pre-training objective, inspired by the Cloze task (Taylor, 1953). The masked language model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked word based only on its context. Unlike left-toright language model pre-training, the MLM objective enables the representation to fuse the left and the right context, which allows us to pretrain a deep bidirectional Transformer.
- BERT는 단방향 학습을 극복하기 위해 “masked language model”(MLM)을 사용했다.
- MLM은 랜덤하게 토큰을 마스킹한 후, 마스킹 된 토큰을 맞추도록 학습시키는 것이다. MLM은 토큰의 순서와 관계 없는 학습이기 때문에 결과적으로 양방향 학습이 된다.
- In addition to the masked language model, we also use a “next sentence prediction” task that jointly pretrains text-pair representations. The contributions of our paper are as follows:
- 또한 “next sentence prediction”(NSP) task를 사용했다.
- NSP는 문장 2개를 짝지운 후, 하나의 문장을 랜덤하게 마스크하고 다음 문장을 맞추도록 학습시키는 것이다.
- We demonstrate the importance of bidirectional pre-training for language representations. Unlike Radford et al. (2018), which uses unidirectional language models for pre-training, BERT uses masked language models to enable pretrained deep bidirectional representations. This is also in contrast to Peters et al. (2018a), which uses a shallow concatenation of independently trained left-to-right and right-to-left LMs.
- BERT는 MSM을 통해 깊은 양방향 학습을 한다. 이는 얕은 양방향 학습(왼쪽 → 오른쪽으로 학습 시킨 후, 다시 오른쪽 → 왼쪽으로 학습시킴)과는 다르다
- We show that pre-trained representations reduce the need for many heavily-engineered task specific architectures. BERT is the first finetuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many task-specific architectures.
- 사전 학습을 이용하면, 특정 task를 위해 많은 노력을 들여 아키텍쳐를 설계할 필요가 없다.
- BERT는 최초의 finetuning 기반의 사전 학습 모델이며, 특정 task를 위해 만들어진 아키텍쳐들의 성능을 능가한다.
- BERT advances the state of the art for eleven NLP tasks. The code and pre-trained models are available at https://github.com/google-research/bert.
- 코드는 여기에
Related Work
- There is a long history of pre-training general language representations, and we briefly review the
most widely-used approaches in this section.
- 사전 학습을 활용한 언어 표현에는 유구한 역사가 있는데, 잠깐 리뷰하겠다.
Unsupervised Feature-based Approaches
- Learning widely applicable representations of words has been an active area of research for decades, including non-neural (Brown et al., 1992; Ando and Zhang, 2005; Blitzer et al., 2006) and neural (Mikolov et al., 2013; Pennington et al., 2014) methods. Pre-trained word embeddings are an integral part of modern NLP systems, offering significant improvements over embeddings learned from scratch (Turian et al., 2010). - 사전 학습된 단어 임베딩을 사용하면 task 성능이 비약적으로 높아진다.
- To pretrain word embedding vectors, left-to-right language modeling objectives have been used (Mnih and Hinton, 2009), as well as objectives to discriminate correct from incorrect words in left and right context (Mikolov et al., 2013)
- 단어 임베딩 벡터를 사전 학습시키기 위해, 단어의 바로 다음(오른쪽)에 출현하는 단어가 적절한지 판단하는 방식을 사용했다.
- These approaches have been generalized to coarser granularities, such as sentence embeddings (Kiros et al., 2015; Logeswaran and Lee, 2018) or paragraph embeddings (Le and Mikolov, 2014). To train sentence representations, prior work has used objectives to rank candidate next sentences (Jernite et al., 2017; Logeswaran and Lee, 2018), left-to-right generation of next sentence words given a representation of the previous sentence (Kiros et al., 2015), or denoising autoencoder derived objectives (Hill et al., 2016).
- 이런 접근 방식은 문장 임베딩, 문단 임베딩에도 응용되었다.
- 문장 표현을 사전 학습하기 위해, 다음에 출현할 문장 후보들의 랭킹 매기기, 현재 문장 표현을 주고 다음에 출현할 문장의 단어를 왼쪽 → 오른쪽 방향으로 생성하기, 오토 인코더의 노이즈 제거하기 등의 방법을 사용했었다.
- ELMo and its predecessor (Peters et al., 2017, 2018a) generalize traditional word embedding research along a different dimension. They extract context-sensitive features from a left-to-right and a right-to-left language model. The contextual representation of each token is the concatenation of the left-to-right and right-to-left representations. When integrating contextual word embeddings with existing task-specific architectures, ELMo advances the state of the art for several major NLP benchmarks (Peters et al., 2018a) including question answering (Rajpurkar et al., 2016), sentiment analysis (Socher et al., 2013), and named entity recognition (Tjong Kim Sang and De Meulder, 2003).
- ELMo는 왼쪽 → 오른쪽 방향의 언어 모델과 오른쪽 → 왼쪽 방향의 언어 모델을 조합해서 문맥을 잘 표현할 수 있는 단어 임베딩을 선보였고, state-of-the-art를 달성했다. 이는 얕은 양방향 학습이다.
- Melamud et al. (2016) proposed learning contextual representations through a task to predict a single word from both left and right context using LSTMs. Similar to ELMo, their model is feature-based and not deeply bidirectional.
- LSTM 기반, 양방향 단어를 맞추는 작업을 통해 문맥을 표현하는 방식도 제안되었는데, 이는 ELMo와 비슷한 개념이며, 역시 얕은 양방향 학습이다.
- Fedus et al. (2018) shows that the cloze task can be used to improve the robustness of text generation models.
- cloze task(문장 내 제거된 단어를 맞추는 task)이 문장 생성 모델의 신뢰도를 높여준다.
Unsupervised Fine-tuning Approaches
- As with the feature-based approaches, the first works in this direction only pre-trained word embedding parameters from unlabeled text (Collobert and Weston, 2008).
- 처음에는 fine-tuning 접근법에서도 feature-based 접근법 처럼 단어 임베딩 파라미터들만 사전 학습되었다.
- More recently, sentence or document encoders which produce contextual token representations have been pre-trained from unlabeled text and fine-tuned for a supervised downstream task (Dai and Le, 2015; Howard and Ruder, 2018; Radford et al., 2018).
- 이후 문맥을 표현하는 토큰들을 출력하는 문장 및 문서 인코더들이 사전 학습 되었고, 특정 목적을 가진 지도 학습 task를 위해 fine-tuning 되었다.
- The advantage of these approaches is that few parameters need to be learned from scratch. At least partly due to this advantage, OpenAI GPT (Radford et al., 2018) achieved previously state-of-the-art results on many sentence level tasks from the GLUE benchmark (Wang et al., 2018a). Left-to-right language modeling and auto-encoder objectives have been used for pre-training such models (Howard and Ruder, 2018; Radford et al., 2018; Dai and Le, 2015).
- 이 방식의 장점은 아예 처음부터 학습해야하는 파라미터가 거의 없다는 것이다.(학습된 파라미터들을 이미 다 가지고 있다.) OpenAI GPT는 이런 장점을 활용해서 많은 문장 레벨 NLP 작업들에서 state-of-the-art를 달성했다.
- 사전 학습을 위해 텍스트를 왼쪽 → 오른쪽 방향으로 학습한 언어 모델과 오토 인코더 등이 사용되었다.
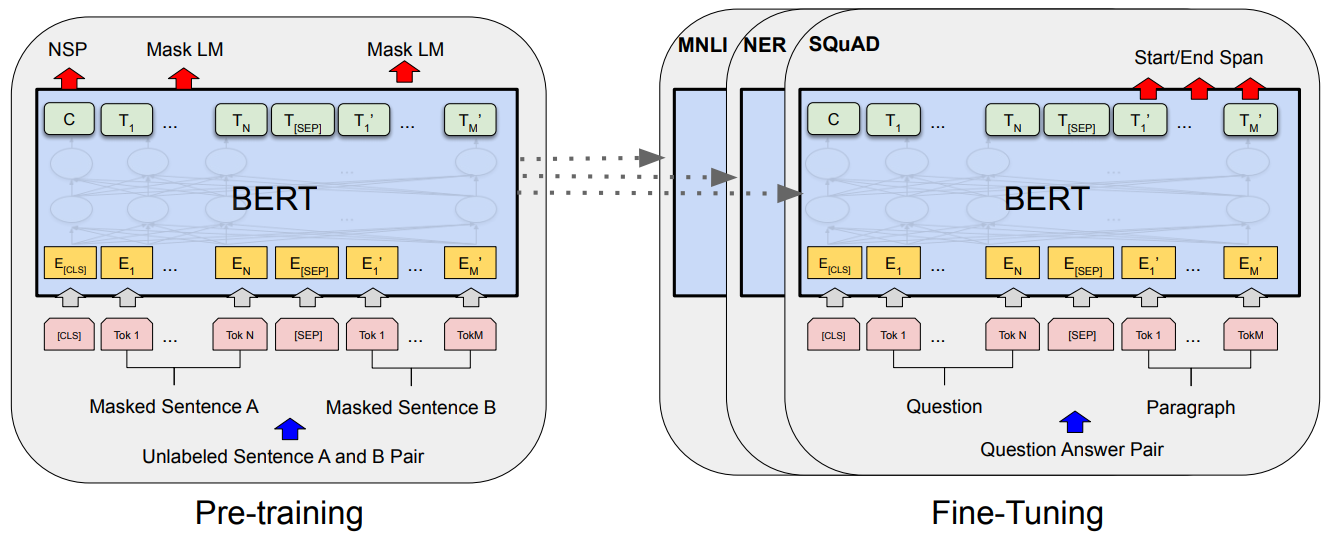
- Figure 1: Overall pre-training and fine-tuning procedures for BERT. Apart from output layers, the same architectures are used in both pre-training and fine-tuning. The same pre-trained model parameters are used to initialize models for different down-stream tasks. During fine-tuning, all parameters are fine-tuned. [CLS] is a special symbol added in front of every input example, and [SEP] is a special separator token (e.g. separating questions/answers).
- 출력 레이어를 제외하면 pre-training과 fine-tuining의 아키텍쳐는 같다.
- 다른 목적을 가진 여러 task들(MNLI, NER, SQuAD, …)에 같은 pre-training 모델 파라미터들을 사용할 수 있다.
- fine-tuning 중에 모든 파라미터들이 미세 조정된다.
Transfer Learning from Supervised Data
- There has also been work showing effective transfer from supervised tasks with large datasets, such as natural language inference (Conneau et al.,2017) and machine translation (McCann et al.,2017). Computer vision research has also demonstrated the importance of transfer learning from large pre-trained models, where an effective recipe is to fine-tune models pre-trained with ImageNet (Deng et al., 2009; Yosinski et al., 2014).
- 자연어 추론, 기계 번역 등, 큰 데이터 셋을 사용한 지도 학습으로부터 전이 학습의 효과를 확인했다.
- 사전 학습된 큰 모델로부터의 전이 학습이 중요하다는 것이 컴퓨터 비전 리서치에서도 증명되었다.
BERT
- We introduce BERT and its detailed implementation in this section. There are two steps in our framework: pre-training and fine-tuning. During pre-training, the model is trained on unlabeled data over different pre-training tasks. For finetuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks. Each downstream task has separate fine-tuned models, even though they are initialized with the same pre-trained parameters. The question-answering example in Figure 1 will serve as a running example for this section. A distinctive feature of BERT is its unified architecture across different tasks. There is minimal difference between the pre-trained architecture and the final downstream architecture.
- 사전 학습(레이블링 되지 않은 데이터로 학습) + 미세 조정(task의 목적에 맞게 레이블링 된 데이터로 학습)
- 사전 학습시 학습했던 파라미터 중, 미세 조정 task에 필요한 것들만 뽑아서 미세 조정 과정에서 추가 학습 시킴
- 사전 학습에 포함된 파라미터들은 여러 미세 조정 task에 대응할 수 있게 설계되었다.
Model Architecture
- BERT’s model architecture is a multi-layer bidirectional Transformer encoder based on the original implementation described in Vaswani et al. (2017) and released in the tensor2tensor library.1 Because the use of Transformers has become common and our implementation is almost identical to the original, we will omit an exhaustive background description of the model architecture and refer readers to Vaswani et al. (2017) as well as excellent guides such as “The Annotated Transformer.”2 In this work, we denote the number of layers (i.e., Transformer blocks) as L, the hidden size as H, and the number of self-attention heads as A. 3 We primarily report results on two model sizes: BERTBASE (L=12, H=768, A=12, Total Parameters=110M) and BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M). BERTBASE was chosen to have the same model size as OpenAI GPT for comparison purposes. Critically, however, the BERT Transformer uses bidirectional self-attention, while the GPT Transformer uses constrained self-attention where every token can only attend to context to its left.
- BERT는 트랜스포머의 인코더 부분을 차용했다. Transformers 인코더 구조 참조
- L
- 레이어 수(트랜스포머 블럭의 수)
- H
- 히든 사이즈(토큰 벡터의 표현 해상도)
- A
- 어텐션 헤드 수(트랜스포머의 셀프 어텐션 헤드 수)
- BERTBASE의 모델 크기
- L=12, H=768, A=12, 총 파라미터 수=110M
- 비교를 위해 OpenAI GPT의 모델 크기에 맞췄다.
- BERTLARGE의 모델 크기
- L=24, H=1024, A=16, 총 파라미터 수=340M
Input/Output Representations
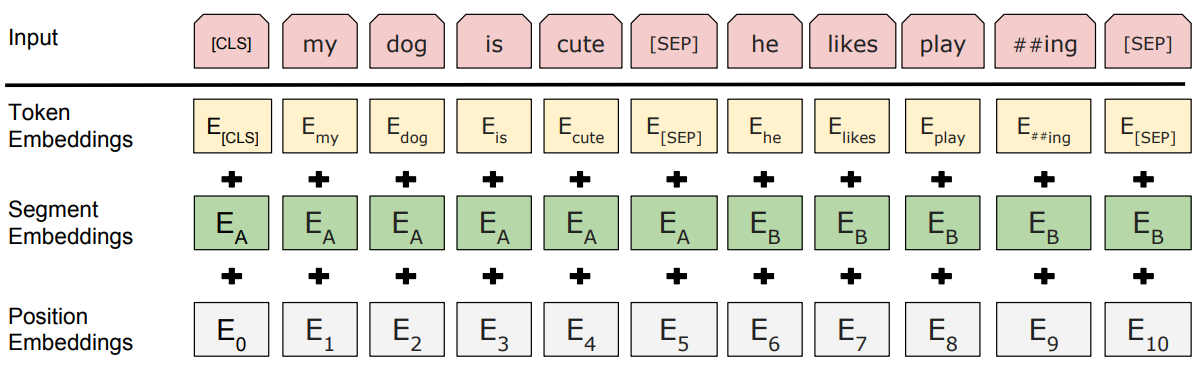
- To make BERT handle a variety of down-stream tasks, our input representation is able to unambiguously represent both a single sentence and a pair of sentences (e.g., h Question, Answeri) in one token sequence. Throughout this work, a “sentence” can be an arbitrary span of contiguous text, rather than an actual linguistic sentence. A “sequence” refers to the input token sequence to BERT, which may be a single sentence or two sentences packed together. We use WordPiece embeddings (Wu et al., 2016) with a 30,000 token vocabulary. The first token of every sequence is always a special classification token ([CLS]). The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks. Sentence pairs are packed together into a single sequence. We differentiate the sentences in two ways. First, we separate them with a special token ([SEP]). Second, we add a learned embedding to every token indicating whether it belongs to sentence A or sentence B. As shown in Figure 1, we denote input embedding as E, the final hidden vector of the special [CLS] token as \(C \in R^{H}\), and the final hidden vector for the \(i^{th}\) input token as \(T_i \in R^{H}\). For a given token, its input representation is constructed by summing the corresponding token, segment, and position embeddings. A visualization of this construction can be seen in Figure 2
- 입력 데이터 형식은 “[CLS]첫번째 시퀀스 토큰들[SEP]두번째 시퀀스 토큰들” 이다.
- 시퀀스는 단일 문장이 될 수도 있고, 복수 문장이 될 수도 있다. 시퀀스는 토큰들로 표현한다.
- 시퀀스를 토큰으로 표현할 때, 약 30,000개의 토큰 어휘를 갖는 WordPiece 토크나이저를 사용한다.
- [CLS]는 하나의 입력 데이터가 시작됨을 나타내는 스페셜 토큰이다. 하나의 입력 데이터를 대표하므로, 이 토큰의 마지막 히든 벡터를 시퀀스 분류 fine-tuning task의 입력으로 사용할 수 있다.
- [SEP]는 하나의 입력 데이터 내에서 두 개의 시퀀스를 구분해야 하는 task(Q&A task 등)에서 두 시퀀스를 구분하기 위해 사용하는 스페셜 토큰이다. 따라서 task에 따라 필요할 수도 있고 그렇지 않을 수도 있다.
- 입력 토큰의 임베딩 = 토큰 ID(0 ~ 약 30,000) + 토큰의 시퀀스 ID(0 ~ 1) + 시퀀스 내 토큰 위치(0 ~ 511)
Pre-training BERT
- Unlike Peters et al. (2018a) and Radford et al. (2018), we do not use traditional left-to-right or right-to-left language models to pre-train BERT. Instead, we pre-train BERT using two unsupervised tasks, described in this section. This step is presented in the left part of Figure 1.
- 얕은 양방향 학습 안쓰고, 2가지 방식의 비지도 task를 쓴다.
Task #1: Masked LM
- Intuitively, it is reasonable to believe that a deep bidirectional model is strictly more powerful than either a left-to-right model or the shallow concatenation of a left-toright and a right-to-left model. Unfortunately, standard conditional language models can only be trained left-to-right or right-to-left, since bidirectional conditioning would allow each word to indirectly “see itself”, and the model could trivially predict the target word in a multi-layered context.
- 단방향 또는 얕은 양방향 학습보다 깊은 양방향 학습이 좋다.
- In order to train a deep bidirectional representation, we simply mask some percentage of the input tokens at random, and then predict those masked tokens. We refer to this procedure as a “masked LM” (MLM), although it is often referred to as a Cloze task in the literature (Taylor, 1953). In this case, the final hidden vectors corresponding to the mask tokens are fed into an output softmax over the vocabulary, as in a standard LM.
- 깊은 양방향 학습을 위해 입력 토큰의 일부를 마스킹하고, 마스킹한 토큰을 맞추도록 한다. 이를 MLM이라고 한다.
- In all of our experiments, we mask 15% of all WordPiece tokens in each sequence at random. In contrast to denoising auto-encoders (Vincent et al., 2008), we only predict the masked words rather than reconstructing the entire input.
- 각 시퀀스 내 토큰의 15%를 랜덤하게 마스킹했다.
- 오토 인코더의 노이즈 제거와는 달리, 전체 입력을 재구성하지 않고 오직 마스킹 된 단어만 맞춘다.
- Although this allows us to obtain a bidirectional pre-trained model, a downside is that we are creating a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. To mitigate this, we do not always replace “masked” words with the actual [MASK] token. The training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, we replace the \(i^{th}\) token with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged \(i^{th}\) token 10% of the time. Then, \(T_i\) will be used to predict the original token with cross entropy loss. We compare variations of this procedure in Appendix C.2.
- 토큰의 15%를 선택하고, 선택한 토큰을 [MASK] 토큰으로 바꾼다.
- 미세 조정에서는 [MASK] 토큰을 사용하지 않기 때문에, 사전 학습과 미세 조정 사이에 불균형이 발생한다. 이를 완화시키기 위해, 선택한 토큰을 일정 확률로 [MASK] 토큰이 아닌 다른 토큰으로 바꾼다.
- 80% 확률로 [MASK] 토큰
- 10% 확률로 랜덤 토큰
- 10% 확률로 안바꿈
- 바꾼 토큰의 마지막 히든 벡터(\(T_i\))와 원래 토큰 벡터의 크로스 엔트로피 손실률이 최소가 되도록 학습시킨다.
Task #2: Next Sentence Prediction (NSP)
- Many important downstream tasks such as Question Answering (QA) and Natural Language Inference (NLI) are based on understanding the relationship between two sentences, which is not directly captured by language modeling. In order to train a model that understands sentence relationships, we pre-train for a binarized next sentence prediction task that can be trivially generated from any monolingual corpus.
- QA, NLI등은 문장간의 관계를 알아야 가능하다.
- 문장간의 관계를 학습시키기 위해 2개의 문장을 주고 이어지는 문장인지 아닌지 맞추도록 학습시켰다.
- Specifically, when choosing the sentences A and B for each pretraining example, 50% of the time B is the actual next sentence that follows A (labeled as IsNext), and 50% of the time it is a random sentence from the corpus (labeled as NotNext). As we show in Figure 1, C is used for next sentence prediction (NSP).5 Despite its simplicity, we demonstrate in Section 5.1 that pre-training towards this task is very beneficial to both QA and NLI.
- 2개의 문장 중, 두번째 문장을 첫번째 문장에 원래 이어지는 문장 50%, 무작위 문장 50%으로 설정하여 학습시켰다.
- The NSP task is closely related to representationlearning objectives used in Jernite et al. (2017) and Logeswaran and Lee (2018). However, in prior work, only sentence embeddings are transferred to down-stream tasks, where BERT transfers all parameters to initialize end-task model parameters.
- 비슷한 이전 모델들에서는 문장의 임베딩 값만 다운스트림 task로 넘겼는데, BERT는 모든 파라미터를 다운스트림 task로 넘긴다.
Pre-training data
- The pre-training procedure largely follows the existing literature on language model pre-training. For the pre-training corpus we use the BooksCorpus (800M words) (Zhu et al., 2015) and English Wikipedia (2,500M words). For Wikipedia we extract only the text passages and ignore lists, tables, and headers. It is critical to use a document-level corpus rather than a shuffled sentence-level corpus such as the Billion Word Benchmark (Chelba et al., 2013) in order to extract long contiguous sequences.
- 사전 학습에 인터넷 책, 영어 위키피디아(표, 그래프 등을 제외한 텍스트만) 문장들을 사용했다.
- Billion Word Benchmark 처럼 문장이 랜덤하게 섞인 코퍼스보다는 문서 수준(여러 문장들이 연관성을 갖고 뭉쳐있는)의 코퍼스를 사용하는 것이 매우 중요하다.
Fine-tuning BERT
- Fine-tuning is straightforward since the self attention mechanism in the Transformer allows BERT to model many downstream tasks— whether they involve single text or text pairs—by swapping out the appropriate inputs and outputs.
- 미세 조정은 단순한 구조이다. 트랜스포머의 셀프 어텐션 메커니즘은 다양한 다운스트림 task에 대응할 수 있기 때문이다.
- For applications involving text pairs, a common pattern is to independently encode text pairs before applying bidirectional cross attention, such as Parikh et al. (2016); Seo et al. (2017). BERT instead uses the self-attention mechanism to unify these two stages, as encoding a concatenated text pair with self-attention effectively includes bidirectional cross attention between two sentences.
- 문장 쌍이 필요한 task에서는 보통 각각의 문장을 따로 인코딩하여 양방향 교차 셀프 어텐션을 시키지만, BERT에서는 두 단계를 통합했다.
- 셀프 어텐션 된 두 문장을 한번에 쌍으로 인코딩하면, 두 문장 사이에 양방향 교차 셀프 어텐션이 효과적으로 적용된다.
- For each task, we simply plug in the task specific inputs and outputs into BERT and finetune all the parameters end-to-end.
- 원하는 task에 따라 입력/출력 형식만 맞춰 BERT에 넣어주면 BERT의 모든 파라미터들이 미세 조정된다.
- At the input, sentence A and sentence B from pre-training are analogous to (1) sentence pairs in paraphrasing, (2) hypothesis-premise pairs in entailment, (3) question-passage pairs in question answering, and (4) a degenerate text-∅ pair in text classification or sequence tagging.
- 사전 학습에서 문장쌍(문장A + 문장B) 형식의 입력은 (1) 유사한 의미의 문장 2개 (2) 가설/전제 문장 (3) 질문/응답 문장 (4) 문서 분류나 문장 태깅에서 ‘텍스트-∅ 쌍’ 등이 될 수 있다.
- At the output, the token representations are fed into an output layer for tokenlevel tasks, such as sequence tagging or question answering, and the [CLS] representation is fed into an output layer for classification, such as entailment or sentiment analysis.
- 출력에서 토큰 표현은 토큰 수준 task(문장 태깅, 질문/응답)들의 입력 값이 될 수 있다.
- [CLS] 토큰은 감정 분류와 같은 task에 입력 값이 될 수 있다.
- Compared to pre-training, fine-tuning is relatively inexpensive. All of the results in the paper can be replicated in at most 1 hour on a single Cloud TPU, or a few hours on a GPU, starting from the exact same pre-trained model.7 We describe the task-specific details in the corresponding subsections of Section 4. More details can be found in Appendix A.5.
- 사전 학습에 비해 미세 조정은 쉽고 빠르다.
Experiments
GLUE
SQuAD v1.1
SQuAD v2.0
SWAG
Ablation Studies
- In this section, we perform ablation experiments over a number of facets of BERT in order to better understand their relative importance. Additional ablation studies can be found in Appendix C. - BERT를 더 잘 이해하기 위해 BERT의 몇몇 부분을 제거하면서 테스트 해봤다.
Effect of Pre-training Tasks
- We demonstrate the importance of the deep bidirectionality of BERT by evaluating two pretraining objectives using exactly the same pretraining data, fine-tuning scheme, and hyperparameters as BERTBASE:
- 깊은 양방향 학습의 중요성을 살펴보자
- BERTBASE라는 동일한 조건에서 2가지 사전 학습 방식을 비교해본다.
- No NSP: A bidirectional model which is trained using the “masked LM” (MLM) but without the “next sentence prediction” (NSP) task.
- MLM은 하고 NSP는 안하고
- LTR & No NSP: A left-context-only model which is trained using a standard Left-to-Right (LTR) LM, rather than an MLM. The left-only constraint was also applied at fine-tuning, because removing it introduced a pre-train/fine-tune mismatch that degraded downstream performance. Additionally, this model was pre-trained without the NSP task. This is directly comparable to OpenAI GPT, but using our larger training dataset, our input representation, and our fine-tuning scheme.
- MLM대신 단방향(왼쪽 → 오른쪽) 학습을 하고 NSP는 안하고
- 단방향 학습은 사전 학습, 미세 조정에 모두 적용
- OpenAI GPT와 구조적으로 직접 비교가 가능하다.(데이터셋의 크기 등은 다르지만…)
- We first examine the impact brought by the NSP task. In Table 5, we show that removing NSP hurts performance significantly on QNLI, MNLI, and SQuAD 1.1.
- NSP가 얼마나 영향을 미치는지 QNLI, MNLI, SQuAD 1.1를 통해 알아봤다.
- Next, we evaluate the impact of training bidirectional representations by comparing “No NSP” to “LTR & No NSP”. The LTR model performs worse than the MLM model on all tasks, with large drops on MRPC and SQuAD. For SQuAD it is intuitively clear that a LTR model will perform poorly at token predictions, since the token-level hidden states have no rightside context.
- 깊은 양방향 학습과 단방향 학습이 얼마나 차이가 나는지 알아봤는데, 모든 task에서 단방향 학습의 성능이 떨어졌고, 특히 MRPC와 SQuAD에서는 더 떨어졌다.
- 토큰 예측에서 단방향 학습의 성능이 확실히 떨어지는데, 토큰 수준의 히든 상태는 오른쪽 문맥을 전혀 알지 못하기 때문이다.
- In order to make a good faith attempt at strengthening the LTR system, we added a randomly initialized BiLSTM on top. This does significantly improve results on SQuAD, but the results are still far worse than those of the pretrained bidirectional models.
- 단방향 학습을 좀 더 개선하기 위해 BiLSTM을 최상위에 추가했는데, SQuAD에서 성능이 확실히 올라가긴 하지만 여전히 사전 학습된 양방향 모델보다는 떨어진다.
- The BiLSTM hurts performance on the GLUE tasks. We recognize that it would also be possible to train separate LTR and RTL models and represent each token as the concatenation of the two models, as ELMo does. However: (a) this is twice as expensive as a single bidirectional model; (b) this is non-intuitive for tasks like QA, since the RTL model would not be able to condition the answer on the question; (c) this it is strictly less powerful than a deep bidirectional model, since it can use both left and right context at every layer.
- ELMo와 비슷하게 단방향 학습 2개를 따로 학습시킨다음에 조합하는 것도 해봤는데
- (a) 비용이 많이 들고, (b) QA와 같은 task에서는 별로이고(오른쪽 → 왼쪽 단방향 모델은 질문에대한 답 조건을 만들 수가 없다.) (c) 모든 층에서 왼쪽과 오른쪽 문맥을 다 사용하기 때문에 성능이 떨어진다.
Effect of Model Size
- In this section, we explore the effect of model size on fine-tuning task accuracy. We trained a number of BERT models with a differing number of layers, hidden units, and attention heads, while otherwise using the same hyperparameters and training procedure as described previously. Results on selected GLUE tasks are shown in Table 6. In this table, we report the average Dev Set accuracy from 5 random restarts of fine-tuning.
- 레이어 수, 히든 벡터 수, 어텐션 헤드 수에 따라 성능이 어떻게 달라지는지 알아봤다.(그 외 하이퍼파라미터는 동일)
- 랜덤하게 5번 미세 조정을 해서 평균을 구했다.
- We can see that larger models lead to a strict accuracy improvement across all four datasets, even for MRPC which only has 3,600 labeled training examples, and is substantially different from the pre-training tasks.
- 큰 모델이 모든 데이터셋에서 좋은 성능을 낸다.
- It is also perhaps surprising that we are able to achieve such significant improvements on top of models which are already quite large relative to the existing literature. For example, the largest Transformer explored in Vaswani et al. (2017) is (L=6, H=1024, A=16) with 100M parameters for the encoder, and the largest Transformer we have found in the literature is (L=64, H=512, A=2) with 235M parameters (Al-Rfou et al., 2018). By contrast, BERTBASE contains 110M parameters and BERTLARGE contains 340M parameters. It has long been known that increasing the model size will lead to continual improvements on large-scale tasks such as machine translation and language modeling, which is demonstrated by the LM perplexity of held-out training data shown in Table 6.
- 기계 번역이나 언어 모델링에서는 더 큰 모델이 더 좋은 성능을 낸다는 것을 알지만,
- However, we believe that this is the first work to demonstrate convincingly that scaling to extreme model sizes also leads to large improvements on very small scale tasks, provided that the model has been sufficiently pre-trained.
- 극단적으로 작은 규모의 task에서도 성능이 좋아질 수 있다는 것은 이번에 BERT가 처음 입증했다. Peters et al. (2018b) presented mixed results on the downstream task impact of increasing the pre-trained bi-LM size from two to four layers and Melamud et al. (2016) mentioned in passing that increasing hidden dimension size from 200 to 600 helped, but increasing further to 1,000 did not bring further improvements.
- 기존의 feature에 기반한 학습에서는 모델이 일정 크기가 되면 더이상 성능이 좋아지지 않았다. Both of these prior works used a featurebased approach — we hypothesize that when the model is fine-tuned directly on the downstream tasks and uses only a very small number of randomly initialized additional parameters, the taskspecific models can benefit from the larger, more expressive pre-trained representations even when downstream task data is very small.
- 그러나 BERT처럼 다운스트림 task에서 모든 파라미터가 미세 조정되고, 최소한의 파라미터들만 추가 된다면, 작은 규모의 task에서도 성능이 좋아질 수 있다.
Feature-based Approach with BERT
- All of the BERT results presented so far have used the fine-tuning approach, where a simple classification layer is added to the pre-trained model, and all parameters are jointly fine-tuned on a downstream task.
- 지금까지는 다운스트림 task에서 모든 파라미터를 미세 조정하는 방식을 보여줬다.
- However, the feature-based approach, where fixed features are extracted from the pretrained model, has certain advantages.
- 하지만 사전 학습된 모델에서 특징을 추출해서 고정된 모델을 만드는 방식도 몇가지 장점을 가지고 있다.
- First, not all tasks can be easily represented by a Transformer encoder architecture, and therefore require a task-specific model architecture to be added.
- 먼저, 트랜스포머의 인코더 구조가 모든 것을 표현할 수는 없다. 원하는 task에 맞게 모델의 아키텍쳐를 꾸며야 할 때도 있다.
- Second, there are major computational benefits to pre-compute an expensive representation of the training data once and then run many experiments with cheaper models on top of this representation.
- 또한 사전 학습 모델을 통해 뽑아낸 표현을 이용하면, 학습 데이터의 표현을 얻는데 드는 비용을 줄일 수 있다.
- In this section, we compare the two approaches by applying BERT to the CoNLL-2003 Named Entity Recognition (NER) task (Tjong Kim Sang and De Meulder, 2003).
- NER task에서 2가지 방식을 비교해봤다.
- In the input to BERT, we use a case-preserving WordPiece model, and we include the maximal document context provided by the data. Following standard practice, we formulate this as a tagging task but do not use a CRF layer in the output. We use the representation of the first sub-token as the input to the token-level classifier over the NER label set.
- BERT에 입력 할 때 대소 문자를 구분하는 WordPiece 모델을 사용했다.
- 출력에 CRF 층을 사용하지 않았다.
- 토큰 수준 분류기의 입력으로 첫 번째 서브 토큰의 표현을 사용했고, NER 레이블 세트를 이용했다.
- To ablate the fine-tuning approach, we apply the feature-based approach by extracting the activations from one or more layers without fine-tuning any parameters of BERT.
- 미세 조정 방식을 제거하고, 특징 추출 방식을 적용했다.
- BERT의 하나 또는 그 이상의 층을 사용했는데, 어떤 파라미터도 미세 조정하지 않았다.
- These contextual embeddings are used as input to a randomly initialized two-layer 768-dimensional BiLSTM before the classification layer.
- 결과로 나온 문맥 임베딩 값을 BiLSTM(2개의 층, 768 차원)의 입력으로 사용했다.
- Results are presented in Table 7. BERTLARGE performs competitively with state-of-the-art methods. The best performing method concatenates the token representations from the top four hidden layers of the pre-trained Transformer, which is only 0.3 F1 behind fine-tuning the entire model. This demonstrates that BERT is effective for both finetuning and feature-based approaches.
- BERTLARGE의 미세 조정 방식이 제일 좋은 성능을 냈지만, 특징 추출 방식도 못지 않은 좋은 성능을 보여준다. F1 점수는 0.3밖에 차이가 안난다.
- 특징 추출 방식에도 BERT가 좋다는 것을 입증했다.
Conclusion
- Recent empirical improvements due to transfer learning with language models have demonstrated that rich, unsupervised pre-training is an integral part of many language understanding systems. In particular, these results enable even low-resource tasks to benefit from deep unidirectional architectures. Our major contribution is further generalizing these findings to deep bidirectional architectures, allowing the same pre-trained model to successfully tackle a broad set of NLP tasks.
- 언어 모델 이용한 전이 학습에는 비지도 사전 학습이 필수다. 리소스가 부족한 task에서도 깊은 단방향 아키텍쳐를 사용할 수 있다.
- 우리는 깊은 양방향 아키텍쳐를 일반화했고, 이는 광범위한 NLP작업에 활용될 수 있다.